
正则表达式
正则表达式(Regular Expression)是用于匹配字符串中字符组合的搜索模式。在JavaScript中,正则表达式也是对象。
正则表达式是程序员必备的瑞士军刀,是衡量前端工程师技术水平的一个侧面标准。而如何高效率地使用正则表达式,是叩门一线互联网公司前必须掌握的知识点。
语法定义
有两种方式创建一个正则表达式:字面量 和RegExp构造函数 。
//采用字面量形式
/pattern/flags
//采用RegExp构造函数之传字面量
new RegExp(pattern [, flags])
//采用RegExp构造函数之传字符串
new RegExp("ab+c",[, flags])上面代码参数说明:
pattern 正则表达式的文本内容。
flags 如果指定,标志可以具有以下值的任意组合:
g全局匹配;找到所有匹配,而不是在第一个匹配后停止;i忽略大小写;m多行;将开始和结束字符(^和$)视为在多行上工作(也就是,分别匹配每一行的开始和结束(由 \n 或 \r 分割),而不只是只匹配整个输入字符串的最开始和最末尾处;uUnicode;将模式视为Unicode序列点的序列;y粘性匹配;仅匹配目标字符串中此正则表达式的lastIndex属性指示的索引(并且不尝试从任何后续的索引匹配);sdotAll模式,匹配任何字符(包括终止符 '\n')。
DFA与NFA
正则表达式是一串很方便的匹配符号,但要实现这么复杂、功能如此强大的匹配语法,就必须要有一套算法来实现,而实现这套算法的东西就叫做正则表达式引擎 。简单地说,正则表达式引擎的有两种实现方式:DFA自动机 (Deterministic Finite Automata,确定的有穷自动机)和 NFA自动机 (Non deterministic Finite Automata,不确定的有穷自动机)。
对于这两种自动机它们的区别,本书并不打算深入挖掘。只简单地说,DFA自动机的时间复杂度是线性的,更加稳定,但是功能有限。而 NFA自动机的时间复杂度比较不稳定,有时候很好,有时候不怎么好,取决于你写的正则表达式。因为NFA胜在功能更加强大,所以包括 Java 、.NET、Perl、Python、Ruby、PHP 等语言,当然也包括本章所讲的JavaScript,都使用了 NFA 去实现其正则表达式引擎。
NFA自动机是以"正则表达式"为基准去匹配的 。为方便后续阅读理解,可以粗略地这样认为:NFA自动机会逐个地读取正则表达式的字符,然后拿去和目标字符串匹配,如果匹配成功就换正则表达式的下一个字符,否则继续和目标字符串的下一个字符比较。
继续阅读前的提醒
多个正则表达式可以匹配同一个字符串,并不意味着它们的运行速度是一样的,有快有慢。
如何写出运行速度较快的正则表达式,实际上有很多优化办法,本篇将重点展开讲述。然而正则表达式涵盖的内容相当广泛,细节又非常之多,本篇文章涵盖内容有限,但仍希望这些内容能帮助前端工程师们理解影响正则表达式运行速度的相关因素,掌握编写高效率正则表达式的方法。
笔者假定你已经掌握了基础的正则表达式使用方法,并有一定的实际项目中的使用经验。否则,你需要去找一些正则表达式有关的书籍,系统地把基础知识学习一下,然后再来阅读本篇内容。
正则表达式的运行原理
了解正则表达式的运行原理,对于如何高效地运行它十分必要。正则表达式运行在正则表达式引擎里,该引擎属于JS引擎的一部分。下面分步骤讲述:
第1步. 编译
当我们用字面量或者RegExp构造函数的方式创建一个正则表达式对象,引擎会验证它是否合法,若是,则根据它的内容生成一段计算机可直接执行的机器语言程序,以便后面执行匹配的任务。
提示:
如果把正则表达式对象赋值给一个变量,就不用反复的执行编译过程了。所以一个好的习惯是,用一个变量存储正则表达式对象。
第2步. 找到「开始位置」
当正则表达式进入使用状态,首先就要确定从目标字符串的哪个位置开始搜索。
- 开始位置 一般在目标字符串最开头字符的位置,或者由正则表达式的
lastIndex属性指定。
lastIndex:
当正则表达式带有/g这个flags的时候,正则表达式的lastIndex属性只作为exec和test方法的起始搜索位置。当flags非/g或任何正则表达式作为参数传递给字符串的match、replace、search以及split方法时,会从目标字符串开头字符的位置搜索。
- 当(因为匹配失败)执行完第4步,然后返回到第2步这里的时候,开始位置则在最后一次匹配位置的下一个位置上。开始位置即可在最后一次匹配位置之后,也可以在其之前,“下一个位置”并不意味着一定在“最后一次匹配位置”之后。
第3步. 匹配每个元规则
一旦开始位置确定好,引擎会解析出正则表达式可能包含的元规则(无法再分解的最小的匹配规则),然后将正则表达式的元规则逐个地和目标字符串进行匹配,匹配成功引擎则会“吃掉”匹配的字符串,针然后对剩余的字符串做匹配。
提示:
为方便读者理解,可以把正则表达式引擎想象成一条贪吃蛇,我们用「吃掉」、「吐出」之类的词来分别形象地描述「匹配成功」后、「匹配失败」后引擎所做的操作。
当正则表达式有多个分支(通常是符号|,也属于元规则)的情况,若一个特定的分支匹配失败的时候,引擎会吐出该分支已匹配的字符串,此时引擎在目标字符串的搜索位置,会重新返回到之前尝试匹配分支的位置上,然后,引擎再尝试匹配其它分支。
第4步. 匹配结果
结果为「完全匹配」或者「彻底匹配失败」。
- 如果在字符串当前的位置发现了一个完全匹配(匹配整个正则表达式),那么引擎会返回完全匹配的结果;
- 反之,如果引擎尝试了所有可能的分支都没有匹配到,引擎会回退到第2步,然后从下一个字符重新开始尝试;
- 当字符串的每个字符都经历了上面的第2、第3步,若仍没有完全匹配的话,那引擎会返回彻底匹配失败的结果。
慢在回溯
前面提到了,正则表达式和字符串匹配失败后,引擎会沿着搜索来时的路径吐出字符串,并准备从下一个位置(或者下一个分支)继续搜索,也即回溯 。关于回溯的这个定义也许不太精确,但不必在意,我们只是用它来相对准确地表示正则表达式运算了多少次,说相对准确,是因为总比更粗略地说“很多次”、“极少次”更准确一些。
回溯是正则表达式如此强大的根源,但是,回溯会产生大量的运算,一不小心就会耗尽CPU计算能力。当然,回溯只是影响正则表达式整体性能的一部分原因,但是理解它的工作原理,以及如何最少花地使用它,是编写高效率正则表达式的关键。
1. 分支与回溯
来看看这段代码,演示了处理分支的过程。
/h(ello|i) coffe/.test("hello makai,hi coffe");
//>> true该正则表达式的用意是匹配hello coffe和hi coffe。
① 引擎开始搜索时,会先根据正则表达式的h搜索目标字符串,因为目标字符串首字符恰好是h,所以立刻被吃掉。
② 接下来,分组(ello|i)提供了两个处理分支。
③ 引擎按从左到右的顺序,先选择最左侧的分支,检查ello是否匹配目标字符串中的下一串字符,匹配成功,此时,目标字符串的hello都已被吃掉。
④ 引擎接着将正则表达式的空格与目标字符串中的空格匹配,匹配成功,此时,目标字符串的hello 都已被吃掉。
⑤ 然后引擎匹配正则表达式中的c,由于字符串的下一个位置是m,因此匹配失败。
⑥ 按前面运行原理的分析,此时正则表达式不会停止尝试,引擎会吐出第一个分支已经匹配的字符串ello ,搜索位置会回到最近匹配的位置的下一个位置上(也即首字符h后面的一个位置,也即e的位置),然后尝试搜索第二个分支。
⑦ 正则表达式里的i与目标字符串中的e匹配没有成功,而且也没有更多的分支了,所以引擎认为从字符串的第一个字符开始匹配是无法成功的,因此需要从第二个字符开始重新搜索。
⑧ 引擎在第2~12个字符中都没有找到h,直到第13个字符匹配到了hi中的h,然后会再次进入搜索分支流程。
⑨ 这次没有匹配到hello coffe,但是在引擎匹配失败回溯后,并尝试第二个分支后,匹配到了字符串hi coffe。
⑩ 匹配成功!
2. 量词与回溯
下面这段代码演示了带有量词时的回溯过程。
常用量词有以下:*任意多个;+至少1个;?0或1个;{m,n}m到n个。
(function () {
var aLongString = "<div>《前端内参—挑战Hard模式下的前端面试之旅》</div>" +
"<small>帮助前端工程师们夯实技术以通过一线互联网企业面试。</small>" +
"A book that tell you how to get the <strong>hard-mode</strong>" +
"<small> interview of Front-End done</small>";
//定义一个正则表达式对象
var re = RegExp(/<div>.*<\/div>/, "i");
//返回一个结果数组
var result = re.exec(aLongString);
//输出匹配的结果
console.log(result[0]);//>> <div>《前端内参—挑战Hard模式下的前端面试之旅》</div>
})();上面代码的正则表达式带有贪婪量词*,表示尽可能多的匹配。代码执行后,输出了aLongString字符串开头的第一行。下面详细分析一下匹配的过程:
① 引擎开始搜索时,会从字符串开始位置查找<div>,很快就匹配到了,引擎吃掉目标字符串的前5个字符<div>;
② 接着,引擎要匹配正则表达式里面的.*,.代表除行终止符(\n,\r,\u2028,\u2029)以外的任意字符,*是贪婪量词,匹配0次或多次,并尽可能多的匹配,因此引擎会吃掉aLongString的全部剩余字符。
③ 然后,引擎要匹配正则表达式里的<,此时aLongString结尾已经没有字符可以与之匹配,故匹配失败,发生回溯,引擎吐出1个字符,尝试继续匹配正则表达式里的<,(如此尝试了7次之后)直到回溯到</small>中的首字符<,匹配成功。
④ 接下来,要匹配正则表达式里面的\/,很明显匹配成功,</small>中的</均被引擎吃掉。
⑤ 接着,匹配正则表达式里的d,而目标字符串提供的是s,所以匹配失败,引擎继续回溯,吐出1个之前吃掉的字符;
⑥ 然后执行之前③~⑤,(重复110多次)直到最后匹配aLongString字符串第一行末尾的</div>;
⑦ 终于,整个正则表达式匹配成功,引擎返回结果。
小知识:贪婪模式、懒惰模式、独占模式
正则表达式默认采用的是贪婪模式,表示尽可能多地匹配。
在量词后面直接加上一个问号?就是懒惰模式了,表示尽可能少地匹配。
在量词后面直接加上一个加号+就是独占模式了,表示尽可能多地匹配,但是不回溯。
JavaScript不支持独占模式。
上面贪婪模式的代码,回溯的次数就超级多了,会造成大量的计算浪费,因此可以改成懒惰模式,减少回溯的次数。如下代码:
(function () {
var aLongString = "<div>《前端内参—挑战Hard模式下的前端面试之旅》</div>" +
"<small>帮助前端工程师们夯实技术以通过一线互联网企业面试。</small>" +
"A book that tell you how to get the <strong>hard-mode</strong>" +
"<small> interview of Front-End done</small>";
//注意.*? 仅仅多了一个?号,就变成了懒惰模式,减少了回溯的次数
var re = RegExp(/<div>.*?<\/div>/, "i");
var result = re.exec(aLongString);
console.log(result[0]);//>> <div>《前端内参—挑战Hard模式下的前端面试之旅》</div>
})();上面的代码,懒惰模式的*?表示尽可能少的匹配,匹配失败也会回溯,只是回溯的方向与贪婪模式下恰好相反:贪婪模式会从字符串末尾往开头的方向回溯,懒惰模式从字符串开头往末尾的方向回溯。具体分析如下:
① 引擎开始搜索时,会从字符串开始位置查找
② 接着,要匹配正则表达式里面的.*?,*表示匹配0次和多次,?表示处于懒惰模式下,会尽可能少的匹配,也即从0次开始匹配,匹配成功;
③ 然后,要匹配正则表达式里的<,字符串里面提供的字符是《,匹配失败,回溯,正则表达式里的*尝试匹配1次。
④ 下一个开始位置是《右边的前,引擎从这里个位置开始搜索,同上,正则表达式里面的<与字符串里面的前会匹配失败,回溯,正则表达式里的*尝试匹配2次。如此回溯23次,直到搜索到字符串aLongString第一行末尾的</div>,匹配成功。
上面的例子,懒惰模式的回溯次数会少很多,可以数得出来是23次,比贪婪模式下的110多次回溯少了太多。
3. 回溯灾难
若正则表达式在匹配字符串的过程,引起了浏览器的假死,或者CPU占用接近100%,原因可能是发生了回溯灾难(Catastrophic Backtracking)。
量词嵌套
下面举个经典的例子来演示回溯灾难。
//可以试试当被测试的字符串长度为20个的时候,浏览器有没有假死?
//cpu的占用率是否飙升?
/(a+)+b/.test("aaaaaaaaaa");小提示:
推荐使用 RegexBuddy 这个软件来测试正则表达式。
用RegexBuddy测试结果显示,短短10个字母的字符串,就花了3582步的运算量。这是因为量词嵌套时,且引擎搜索到目标字符串尾端的字符后才能确定是否匹配,这种情况下因为回溯,运算量可能是指数级别的 。
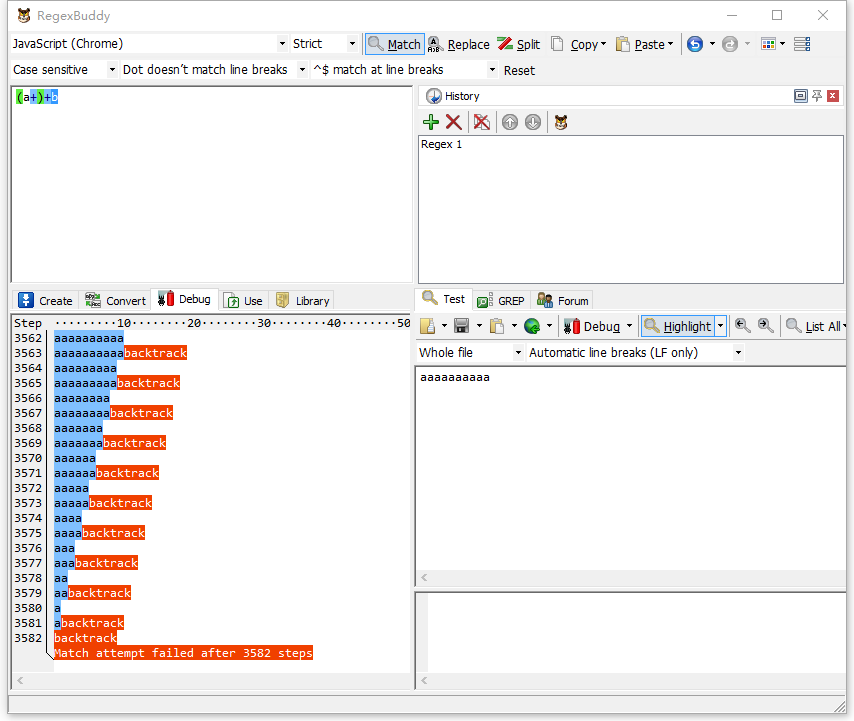
如果测试11个字母的字符串,则会花7166步的运算量,差不多翻倍。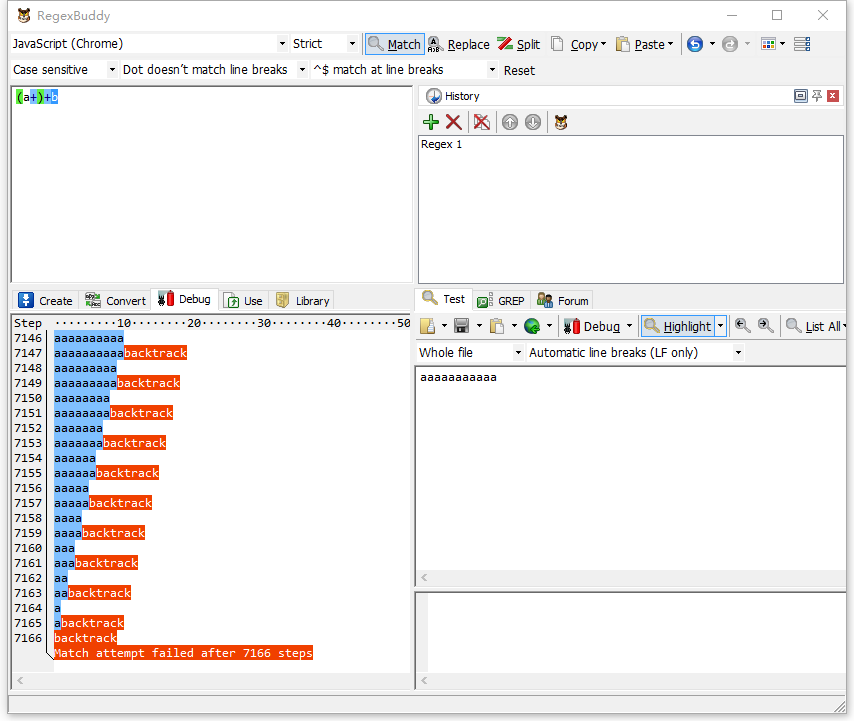
之所以这么多运算量,是因为含有嵌套量词的正则表达式一旦匹配不成功,会有两个回溯:嵌套内的回溯,外面的回溯。它们之间是指数关系。
优化运行效率的办法
基于本篇关于回溯的分析,我们知道了正则表达式运行慢的原因,主要是匹配失败后发生的回溯很慢。当正则表达式匹配一段很长的目标字符串,其中匹配失败的次数比匹配成功的次数多。如果优化修改了一个正则表达式,让它匹配失败的次数变多了,那这个修改是错误的。优化正则表达式,应该尽可能让成功匹配的次数多,让失败匹配的次数少。
下面列出一些提升正则表达式运行效率的办法。
1. 消除量词嵌套
对于量词嵌套的情况,可以用一些优化消除嵌套,如下所示:
var re0 = /(a+)+b/;
//可以优化为
var re1 = /a+b/;
var re2 = /(a*)*/;
//可以优化为
var re3 = /a*/;这样嵌套量词变成不嵌套的形式后,运算量会大大减少,正则表达式运行效率会极大地提升。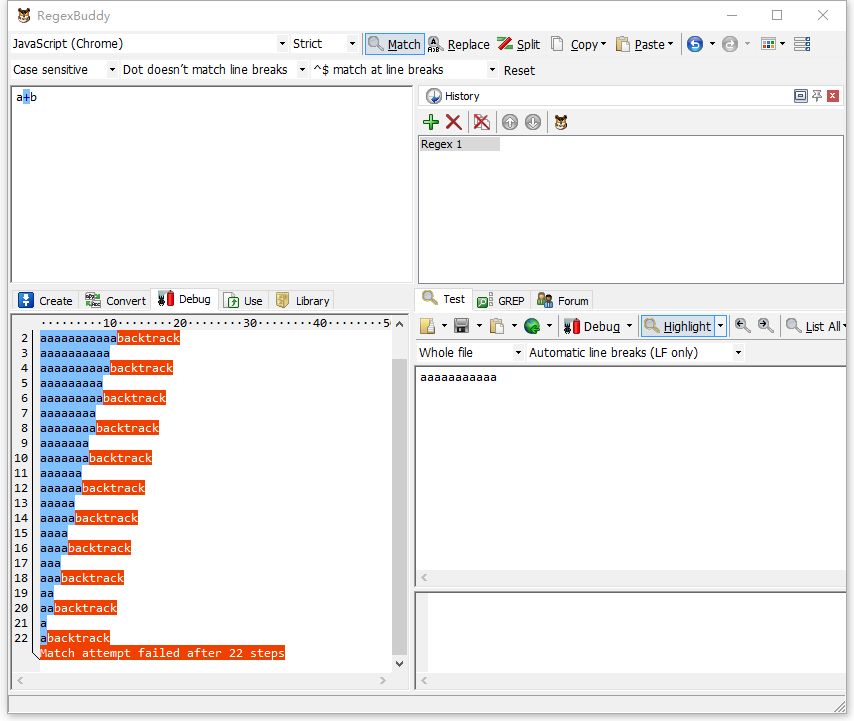
如上图,优化过后的正则表达式只需要运行22步就有了结果。
2. 使用合适的量词
前面的例子已经展示了,使用懒惰模式量词?,会比使用贪婪模式下的量词*减少大量的运算。但这并不是说懒惰模式的量词一定比贪婪模式的量词运行效率高,而是说要基于我们的预期,选择使用合适模式的量词。当我们对回溯的内部行为有了充分了解后,会对回溯的次数有一个基本的预估,基于这个预估,我们再选择使用贪婪模式还是懒惰模式的量词。是的,这个属于“熟能生巧”类型的优化。
3. 将简单必需的字符放在开头
正则表达式的第一个字符应该尽可能快速地排除明显不匹配的位置。比如将锚点(匹配一个位置,^和$、\b等)、字符字面量(匹配具体字符,包括需要转义和不需要转义的)、字符组(比如[a-z]、[A-Z])放在正则表达式的开头是比较好的。
另外避免以分组和分支结构开头,比如避免使用(abc*)或a|b|c这种结构开头,因为它们会强迫正则表达式识别目标字符串中的多种起始字符,造成大量运算。
4. 避免重复编译
前面讲运行原理的时候提到过,把正则表达式赋值给变量以避免对它们重新编译。最主要的是避免在循环体内反复编译正则表达式,代码示例如下:
var str = "coffe1891";
for(var i=0;i<10000;i++){
/^abc*d$/.test(str);//这里会导致引擎重复编译正则表达式
}比较好的做法如下:
var str = "coffe1891";
var re = /^abc*d$/;//将正则表达式赋值给变量,避免引擎重复编译
for(var i=0;i<10000;i++){
re.test(str);
}5. 简化
避免写复杂的正则表达式,也要避免用正则表达式处理复杂的搜索任务。将复杂的正则表达式拆分成多个简单的子正则表达式,让每个子正则表达式在前一个子正则表达式匹配的结果中继续搜索,这样做会更加容易满足需求,而且通常也会有更高的运行效率。
免责声明
本站所有资源出自互联网收集整理,本站不参与制作,如果侵犯了您的合法权益,请联系本站我们会及时删除。
本站发布资源来源于互联网,可能存在水印或者引流等信息,请用户自行鉴别,做一个有主见和判断力的用户。
本站资源仅供研究、学习交流之用,若使用商业用途,请购买正版授权,否则产生的一切后果将由下载用户自行承担。
